Consignes
Le rapport que vous enverrez par TPLab consistera en un unique fichier texte (extension ".txt").
Toutes les réponses contenant une ligne de commande devront être sur une seule ligne précédée d'un caractère "$". (Pour que je puisse les extraire avec ... grep !)
Par exemple :
Pierre Hyvernat TP1 info633 Question 0 ========== Pour obtenir la liste des fichier ".c" dans le répertoire courant, on peut utiliser $ ls *.c Question 1 ========== ... ...
Liens utiles
- un site avec de nombreuses informations et exemples sur les expressions régulières http://www.regular-expressions.info/
- encadrant de TP : Pierre.Hyvernat@univ-savoie.fr
1. Préliminaires : motifs shell
Les motifs du shell contiennent :
| signification | bash |
| joker (1 caractère) | ? |
| joker (plusieurs caractères, éventuellement zéro) | * |
caractère parmi ... |
[...] |
caractère sauf ... |
[!...] |
caractères ? * |
\? \* |
Si votre shell par défaut est différent de bash, il peut y avoir quelques différences. Pour changer le shell courant, vous pouvez utiliser la commande
$ exec bash
dans votre terminal.
La commande
$ ls *.c
permet de lister tous les fichiers dont l'extension est ".c".
- Donnez une commande qui liste tous les fichiers
.cou.h, - donnez une commande pour lister tous les fichiers dont l'avant dernier caractère n'est pas le point "
.", - donnez une commande pour lister tous les fichiers commençant par un point "
.", sauf les répertoires "." et "..". Vous pouvez utiliser plusieurs motifs shell pour ceci. (Remarque : pour quelsn'affiche pas le contenu des répertoires mais uniquement leur nom, il faut ajouter l'argument-dsur la ligne de commande.)
Pour tester, vous pouvez créer des fichiers vides (dans un répertoire temporaire) avec la commande touch:
$ touch fichier1.c Fichier2.h FICHIER3.jpg
Créez les fichiers suivants dans un répertoire temporaire :
$ touch test.jpg test.jpeg index.html test-1.1.jpg test-1.2.jpg tux.png
Certain shells, comme bash, ont des motifs plus perfectionnés. Utilisez la commande suivante pour activer les motifs étendus de bash :
$ shopt -s extglob
Vous pouvez maintenant utiliser un nouveau type de motif : (reportez vous à la section pertinente du manuel de bash pour plus de détails)
| signification | bash |
chaine ne correspondant à aucun motif ... |
!(...|...|...|...) |
- Essayez de deviner le résultat de la commande suivante et expliquez ce que vous constatez lors de son exécution.
$ ls *!(.jpeg|.jpg) ???
- Quel est finalement le langage reconnu par ce motif ?
- Quel motif shell étendu utiliseriez-vous pour obtenir la liste de tous les fichiers sauf les fichiers
.jpget.jpeg?
2. grep
"regex" POSIX: basiques ou étendues
grep est une commande POSIX qui permet
d'afficher les lignes d'un fichier contenant une chaine reconnue par une expression régulière (regex).
L'utilisation courante est
$ grep 'regex' fichier1 fichier2 ...
Les guillemets autour de l'expression régulière ne sont pas toujours obligatoires. Ils évitent au shell de considérer l'expression régulière comme un motif du shell... D'autre part, si aucun fichier n'est donné, grep utilisera l'entrée standard à la place.
Les arguments (optionnels) importants, à mettre avant la regex, sont :
- "
-i" pour préciser de ne pas faire la différence entre minuscules et majuscules, - "
-v" pour n'afficher que les lignes qui ne contiennent pas le motif, - "
-l" pour seulement afficher le nom des fichiers qui contiennent le motif, - "
-c" pour seulement afficher le nombre de lignes contenant le motif, - "
-E" pour préciser que le motif est une expression régulière POSIX étendue.
D'autres arguments optionnels standard (mais non POSIX) bien pratique sont :
- "
-C" suivi d'un nombre, qui permet d'afficher les quelques lignes avant et après les ligne contenant le motif, - "
-r" pour préciser qu'on veut chercher dans les répertoires récursivement.
L'expression régulière peut être donnée soit par :
- une regex "basique" : Basic Regular Expression (BRE),
- une regex "étendue", lorsqu'on donne l'argument "
-E" : Extended Regular Expression (ERE).
Les différences entre les deux sont résumées dans le tableau suivant. Les 6 premières lignes contiennent les notions les plus importantes et sont les même dans les BRE et les ERE. Les différences sont qu'en syntaxe BRE, les autres caractères spéciaux sont précédés d'un antislash.
| signification | BRE | ERE |
| joker (sauf retour chariot) | . |
. |
| répétition | * |
* |
un caractère parmi ... |
[...] |
[...] |
un caractère sauf ... |
[^...] |
[^...] |
| début de ligne | ^ |
^ |
| fin de ligne | $ |
$ |
| groupement | \( \) |
( ) |
| répétition entre m et n fois | \{m,n\} |
{m,n} |
| alternative | \| (non POSIX) |
| |
| répétition, au moins une fois | \+ |
+ |
| zéro ou une occurence d'un motif | \? (non POSIX) |
? |
| référence au n-ème groupe | \1 \2 ... |
\1 \2 ... (non POSIX) |
caractères normaux ( ) [ ] { } | + ? |
( ) [ ] { } | + ? |
\( \) \[ \] \{ \} \| \+ \? |
- Dans les deux cas, un caractère spécial peut être rendu "normal" en l'échappant avec un antislash. Par exemple, "
\$" signifie "le caractère dollar". - Aucun caractère n'a de sens spécial à l'intérieur des crochets, sauf le "
^" (en premier caractère), le "]" (ailleurs qu'en premier caractère). - On peut mettre des raccourcis dans les crochets : "
[abcf-xz]" donnera la même chose que "[abcfghijklmnopqrstuvwxz]". - Il n'y a pas de moyen simple d'ignorer les accents avec
grepseulement.
Pour tester interactivement vos expressions régulières, vous pouvez utiliser la commande suivante :
$ grep -H --label=OK 'regex'
et taper des lignes de texte. Chaque ligne contenant une chaine correspondant à la regex sera réaffichée. (Si la ligne ne correspondait pas, rien n'est affiché...) Pour quitter, il suffit d'appuyer sur la touche "Control" et "c" (en même temps), ou sur la touche "Control" et "d" (en même temps).
Par exemple :
$ grep -H --label=OK 'ab*c' abc <---- ................ OK:abc <---- ligne réaffichée cba <---- ................ cbba <---- ................ abbcdef <---- ................ OK:abbcdef <---- ligne réaffichée
Premiers exercices
La regex "\(aa\)*" (ou "(aa)*" en syntaxe ERE) devrait correspondre à l'ensemble des suites de "a" dont la taille est paire.
Testez cette regex en appelant la command grep (en mode BRE et en mode ERE, càd en ajoutant l'option "-E" sur la ligne de commandes) sur le fichier test.txt contenant les 6 lignes suivantes.
aa aaaa aaaaaa aaa bbbbb CECI EST LA FIN DU FICHIER...
Quelles sont les lignes reconnues par l'expression régulières ? Pourquoi ?
Corrigez la regex pour qu'elle reconnaisse seulement les lignes qui contiennent exactement une suite de a de longueur paire. (Vous devrez utiliser "^" et "$".)
N'oubliez pas de la tester !
Donnez une regex pour reconnaitre les chaines du langage C : elles commencent et terminent par des guillemets " et chaque guillemet " interne doit être précédé d'un antislash.
- exemples de chaines acceptées :
"toto" "C:\\<chemin>\"..." "a\"b'c\'d\\e\\" "" "\"\"\"\"" "abc\n"
- exemples de chaines refusées :
Donnez la ligne de commande que vous utilisez...
"test1 test2" "oups"..." " "abc\"def"\ghi" " " " "a\"b'c\'d\\e\\"" "abc\"
L'antislash "\" est représenté par "\\" dans les regex, sauf lorsqu'il se trouve entre des crochets [...].
(facultatif)
Testez la regex "^a?(ba)*b?([^ab]a?(ba)*b?)*$" sur des chaines et explicitez le langage reconnu.
grep avec un fichier
Le fichier american-english contient les mots courants de la langue anglaise (avec accords et conjugaisons), à raison de un mot par ligne.
Le mot abracadabra contient les lettres a, b, c et d dans l'ordre.
Y'a t'il des mots anglais qui contiennent les lettres a, b, c, d et e dans l'ordre ? (Les autres lettres peuvent être quelconques.)
Donnez l'expression régulière que vous utilisez.
Donner une expression régulière qui liste tout les mots contenant une lettre doublée, comme "blossom" ou "zoom".
Indice : il faudra utiliser un groupe et une référence...
Plus difficile, donnez une expression régulière qui donne les mots avec lettre doublée qui ne sont pas des noms propres. (C'est à dire qui ne commencent pas par une lettre majuscule...) Ces mots contiennent par exemple
llamagammazoo
Y'a t'il des mots anglais contenant une même lettre 6 fois ?
Donnez la ligne de commande que vous utilisez...
grep et redirection
Il est parfois plus pratique d'utiliser plusieurs appels à la commande grep plutôt que de trouver une unique expression régulière. On peut utiliser pour ceci une redirection afin de chercher (avec grep) dans le résultat d'un appel précédent à grep.
Par exemple, on peut obtenir la liste des mots qui contiennent à la fois 2 n et p, dans n'importe quel ordre :
$ grep 'nn' american-english | grep 'pp'
Cherchez la liste des mots anglais qui satisfont les deux conditions suivantes :
- il commencent et terminent par la même lettre,
- il contiennent une lettre répétée au moins 5 fois dans le mots (la première et dernière peuvent compter).
On peut également utiliser grep sur le résultat d'une autre commande arbitraire.
La commande
$ ps aux
affiche la liste de tous les processus existant, avec une multitude d'informations.
Donnez une commande pour afficher la liste des processus des navigateurs internet, c'est à dire dont le nom contient firefox, chromium ou iceweasel.
Améliorez votre ligne de commande pour ne pas afficher les lignes qui ne servent à rien.
3. "regex" et éditeur de texte
La plupart des éditeurs de texte utilisent une bibliothèque d'expressions régulières qui étend les expressions régulières étendues POSIX. C'est notamment le cas de geany et Sublime Text (ainsi que Notepad++) (L'éditeur gedit n'utilise pas de regex sans plugin.)
- dans geany, il ne faut pas oublier de cocher la case "
Utiliser des expressions régulières" dans la fenêtre de recherche, - dans Sublime Text, il ne faut pas oublier d'activer le bouton "
.*" ("Regular Expressions (Alt-R)" tout à gauche dans la barre de recherche.
recherche
Faites une recherche pour visualiser toutes les lignes contenant des caractères blancs (espaces et tabulation) juste avant le retour chariot. Sur le fichier MobyDick.txt, vous devriez obtenir quelque chose comme
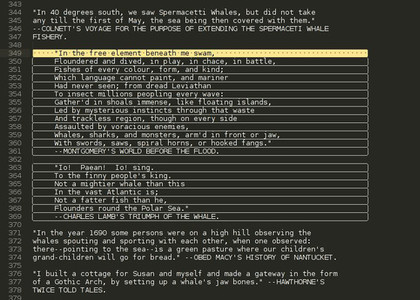 |
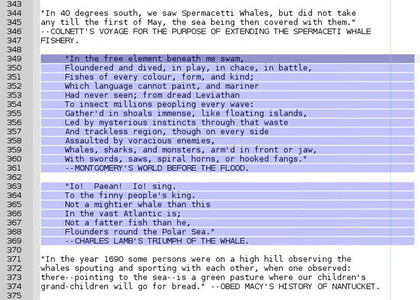 |
| Sublime Text | geany |
Recherchez de la même manière les lignes qui commencent par une tabulation...
substitutions
À l'aide d'un "chercher / remplacer" et d'une expression régulière, supprimez tous les espaces en début de ligne dans le fichier MobyDick.txt.
Vous disposez du fichier csv suivant
NOM, PRÉNOM Allocca, Keith Bengochia, Essie Brooking, Elana Bukowiecki, Lanny Cailler, Santana Cardillo, Shizuko Coello, Miss Dambrosio, Roni Ebadi, Sallie Fernando, Pearl Flaminio, Mayra Flieller, Bibi Gibb, Cesar Hawker, Dusty Isles, Karry Kibler, Francisco Kingcade, Les Korbin, Darby Korner, Humberto Lindelof, Kimberly Madaffari, Illa Mikota, Marvella Pangle, Travis Quijas, Dann Reighard, Valentina Ruman, Dorine Scheide, Dorthea Stetke, Hector Tillery, Lorriane Wolfinbarger, Josue
À l'aide d'une expression régulière et d'un "chercher / remplacer", inversez l'ordre des champs "NOM" et "PRÉNOM" dans tout le fichier.
4. regex et scripts
4.1. sed
Si vous avez besoin de faire des changements simples (comme les chercher / remplacer des questions précédentes) sur de nombreux fichiers, il peut-être pratique d'écrire un script pour automatiser la tache.
Renseignez-vous sur la commande sed
(par exemple, en regardant
la page de manuel "man sed",
la page wikipedia,
le manuel officiel GNU "info sed",
un exemple de tutoriel très complet,
...) et proposez des commandes pour répondre aux questions précédentes (questions 12 et 13) sans éditeur de texte interactif.
Votre solution devra effectuer le "chercher / remplacer" de la question précédente dans tous les fichiers avec l'extension .txt dans le répertoire courant.
N'oubliez pas de commenter votre solution, en donnant en particulier expliquant brièvement chacun des paramètres de la commande sed que vous utilisez.
4.2. AWK
Une autre commande POSIX qui utilise les expressions régulière est AWK (du nom de ses concepteurs: A. Aho, P. Weinberger et B. Kernighan). Il s'agit d'un petit langage de programmation dédié à l'analyse et la mise en forme de données au format texte.
En partant de la page Wikipedia https://en.wikipedia.org/wiki/AWK, regardez comment ce langage fonctionne et proposez une ligne de commande qui
- lance la commande "
ps aux" pour récupérer la liste des processus avec les informations correspondantes, - ne regarde que les ligne concernant l'utilisateur
pierre(à remplacer par votre propre nom d'utilisateur) - fait la somme des pourcentages d'utilisation du processeur
- affiche le résultat final.
Par exemple :
$ ps aux | awk '...' pierre 27.60%
Autrement dit, mes processus utilisent globalement 27% du CPU.


