Consignes
Pour ce TP, vous devrez rendre un petit rapport au format texte comportant vos remarques ainsi que les réponses aux questions posées.
Vous pouvez faire un minimum de mise en page, mais les document Word, OpenOffice ou pdf ne sont pas autorisés !
Liens utiles
-
email des enseignants (Chambéry) francois.boussion@univ-smb.fr, gerald.cavallini@univ-smb.fr, pierre.hyvernat@univ-smb.fr aurelien.senger@soprasteria.com,
-
email des enseignants (Annecy) Jean-Jacques.Curtelin@univ-smb.fr, Sebastien.Monnet@univ-smb.fr
Objectifs du TP
L'objectif de ce TP est de se familiariser avec les concepts liés au réseau.
Préliminaires
1. Adresses IP, DNS, routes, etc.
Chaque ordinateur sur Internet doit être identifié par une adresse IP. Par exemple, l'adresse IP (version 4) du serveur qui héberge le site www.lama.univ-smb.fr est 193.48.121.226
Vérifiez que vous pouvez utiliser l'adresse IP 193.48.121.226 pour aller sur le site du LAMA avec votre navigateur Internet.
DNS
Pour simplifier la vie des utilisateurs, les sites Internet utilisent une adresse "textuelle" :
-
www.univ-smb.fr
-
www.wikipedia.org
-
...
Ces adresses sont traduites en adresses IP en utilisant le protocole DNS
(Domain Name System). Ceci est fait automatiquement par le navigateur web,
mais il est possible de faire une requête DNS directement avec la commande
host.
Quelle est l'adresse IP du site www.linuxfr.org ?
Comparez les addresses IP de
-
www.google.fr
-
www.google.co.nz (Google Nouvelle Zélande)
Ping : temps d'accès
La commande ping permet de mesurer le délai de transmission
entre la machine locale et une machine distante. Cette commande s'utilise
simplement comme suit
$ ping -c 10 ADDRESSet envoie des paquets spéciaux (une dizaine) vers l'adresse donnée, qui renvoie une réponse. La commande affiche le temps de réponse de chaque paquet, et des statistiques finales (temps de réponse minimum, moyen et maximum).
Attention, sans l'option -c 10, la commande continue
d'envoyer des paquets jusqu'à ce qu'on la stoppe à la main. Pour ceci, il faut
utiliser la combinaison "Control-c".
Mesurez le délai de réponse pour atteindre les sites suivants :
-
www.univ-smb.fr (université Savoie Mont Blanc)
-
www.polytech.univ-smb.fr (Polytech Annecy / Chambéry)
-
www.traveljuneau.com (office du tourisme de Juneau, Alaska)
Qu'en pensez vous ?
En particulier, où pensez vous que sont hébergés les serveurs de www.univ-smb.fr et de www.polytech.univ-smb.fr ?
Routes
Les paquets qui voyagent sur Internet sont routés : le chemin qu'ils empruntent est décidé dynamiquement par des routeurs qui essaient de rapprocher les paquets de leur destination finale.
L'utilitaire traceroute permet de visualiser le chemin emprunté
par un paquet pour arriver à une destination. Vous devez l'installer avec
$ sudo apt install traceroutePour l'utiliser, il faut ensuite faire
$ traceroute ADDRESSRegardez la route qu'empruntent les paquets pour aller jusqu'aux adresses IP correspondant aux sites suivants :
-
www.univ-smb.fr (université Savoie Mont Blanc)
-
www.polytech.univ-smb.fr (Polytech Annecy / Chambéry)
Précisez, le nombre de routeurs empruntés par les paquets.
-
si le résultat de traceroute ressemble à ça
1 _gateway ... 2 * * * 3 * * * 4 * * * 5 * * * 6 * * * 7 * * *
il est probable que votre box / firewall refuse les paquets UDP utilisé par traceroute. Dans ce cas, vous pouvez essayer de lancer `traceroute` avec l'option `--icmp` qui utilise ... des paquets ICMP à la place. Attention, il faudra probablement utiliser `sudo` pour avoir les droits nécessaires.
-
L'utilitaire
mtr(qui n'est pas installé par défaut) combinepingettraceroute. Si vous voulez l'utiliser, il suffit de l'installer avec$ sudo apt install mtr-tiny
2. Wireshark
Wireshark est un logiciel qui permet de capturer tout ce qui passe par l'interface réseau (carte Ethernet ou carte WiFi) de votre ordinateur et de l'analyser. Cet outils est intéressant pour les administrateurs d'un réseau, mais aussi pour les pirates qui peuvent ainsi écouter le trafic réseau et chercher des informations utiles.
Vous devez installer Wireshark et donner les droits nécessaires à votre utilisateur :
$ sudo apt install wiresharken choisissant oui à la question Faut-il autoriser les utilisateurs non privilégiés à capturer des paquets ?.
Vous devez ensuite ajouter votre utilisateur au groupe wireshark
sudo adduser UTILISATEUR wiresharkAttention, vous devez vous déconnecter puis vous reconnecter pour activer l'ajout de l'utilisateur au groupe wireshark.
Préliminaire
-
Vérifiez que vous accèdez bien à la version HTTP de cette page. Si l'url commence par https://..., remplacez la par http://...
Si cela ne fonctionne pas, je vous conseille de passer en mode "privé" ("incognito" sous Chrome) et de :
-
désactiver les extensions qui pourraient forcer le passage en https:// (HTTPSeverywhere par exemple)
-
vider le cache et l'historique de navigation (quelque part dans le menu "préferrences").
Attention, si vous accèdez une fois à la version https://, il faudra fermer tous les onglets de la fenêtre privée et en relancer une nouvelle.
-
-
Fermez tous les onglets de votre navigateur Internet pour ne gardez que le sujet du TP. Les autres onglets peuvent générer du trafic qui rendra les informations importantes plus difficiles à trouver...
Lancez le logiciel wireshark. (Si vous le lancez depuis le terminal,
n'oubliez pas de mettre un & à la fin de la ligne pour
récupérer votre shell.)
Vous devriez obtenir quelque chose comme
Dans le menu "Vue" / "View",
-
changez le mode d'affichage du temps ("Format d'Affichage de l'Heure" / "Time Display Format") en choisissant "Heure du jour" / "Time of Day",
-
activez la résolution des noms de domaines ("Résolution de nom" / "Name Resolution") en cochant toutes les cases.
Vous pouvez maintenant sélectionner l'interface connectée au réseau (probablement eth0, eth1 ou eth2 si vous êtes connecté par un câble ethernet, ou un nom bizarre si vous êtes sur une machine virtuelle, enp1s0 lors de mes tests) et lancer la capture en cliquant sur le petit "triangle" en haut à gauche. Vous obtenez quelque chose comme
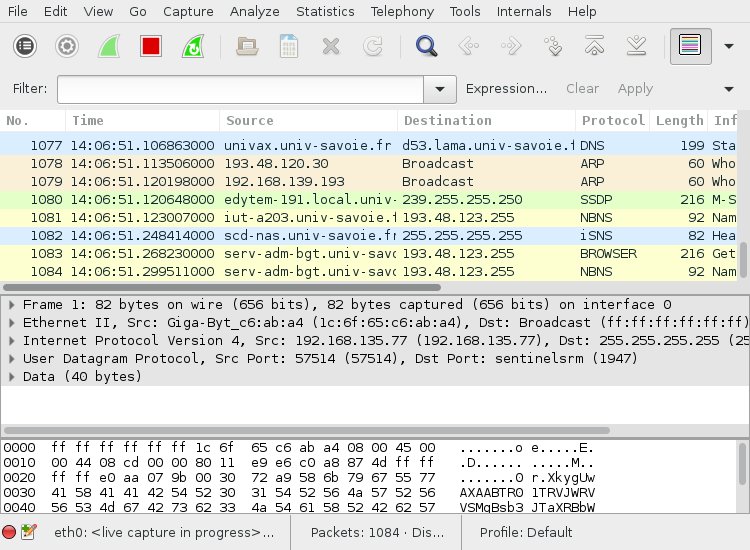
La fenêtre Wireshark est divisée en 3 :
-
la liste des paquets capturés, avec quelques informations (un numéro de paquet, la date de capture, la source et destination, etc.)
-
le contenu "lisible" du paquet, c'est à dire analysé par Wireshark. C'est là qu'on peut lire les métadonnées de chaque paquet, ainsi que ses données (lorsqu'elle sont au format texte).
-
le contenu "brut" du paquet, affiché en hexadécimal.
Vous pouvez supprimer l'affichage du contenu "brut" en désactivant l'option "Paquet Bytes" du menu "View".
Pour limiter l'affichage aux paquets HTTP concernant votre machine, il faut ajouter un filtre : pour ne garder que les paquets en provenance (ou à destination) de votre adresse qui utilisent le protocole HTTP et qui ne sont pas en UDP, on peut ajouter le filtre ip.addr == ADDRESS and http and not udp dans la boite correspondante ("Filter"). "ADDRESS" doit être remplacé par votre adresse IP.
Vous pouvez obtenir votre adresse IP avec la commande
$ ip addressen regardant le champs inet. (Attention, pas pour l'interface lo...)
Appliquez ce filtre, et relancez la capture (carré rouge pour arrêter la capture en cours, et "triangle" vert pour en relancer une nouvelle).
Une fois que la capture est lancée, rechargez la page web du sujet.
-
Combien de requêtes HTTP GET sont effectuées pour recharger la page complète du sujet, et à quoi correspondent ces requêtes ?
-
Quelles sont les réponses de la part du serveur ?
Pendant que la capture précédente fonctionne encore, supprimez le caches des données de votre navigateur (pour Firefox et Chrome, le raccourci clavier est "Control+Shift+Suppr").
Une fois le cache de données vidé, rechargez la page web du sujet.
-
Combien de requêtes HTTP GET sont effectuées pour recharger la page complète du sujet ?
-
Quelles sont les réponses de la part du serveur ?
-
Les paquets correspondant au code HTML contiennent ils des données ?
Cherchez, dans la liste des paquets HTTP, la requête GET pour l'image wireshark2.jpg. Vous pouvez accéder à la réponse du serveur en cliquant sur le lien bleu dans le menu "Hypertext Transfer Protocol" du paquet.
-
Quelle est la taille des données de l'image ?
-
Cette image est trop grosse pour être transférée en un seul paquet TCP. Regardez la réponse du serveur affiché par Wireshark, et donnez le nombre de paquets TCP utilisés pour transférer l'image.
-
Quels sont les ports de destination et de départ des paquets TCP de l'image ? Quelles sont les adresses IP de destination et de départ de l'image ?
Formulaires : méthode POST
Ce petit formulaire est très simple : il permet simplement de choisir une couleur pour le fond de la page.
-
Arrêtez et relancez la capture Wireshark,
-
chargez le formulaire,
-
choisissez une couleur et cliquez sur "Envoyer",
-
arrêtez la capture Wireshark.
-
Regardez le contenu HTML du paquet HTTP dans Wireshark et vérifiez que la couleur choisie est bien envoyée par le formulaire.
-
Faites un "diagramme" de communication en précisant la taille des paquets échangés.
Par exemple, le diagramme pourra contenir
taille description ..... local ------> serveur 571 GET (favicon) local <------ serveur 1907 OK (favicon)
Le formulaire ajoute une vérification de mot de passe... (Vous pouvez utiliser n'importe quel login, et le mot de passe doit simplement commencer par la même lettre que le login...)
Refaites la question précédente avec ce nouveau formulaire.
Qu'en pensez vous ?
Authentification
La page suivante est protégée par un mot de passe.
Relancez la capture de paquets et connectez vous avec l'utilisateur baleine et le mot de passe poum.
Inspectez les paquets capturés par Wireshark et vérifiez que le mot de passe est envoyé en clair avec la requête GET.
Qu'en pensez vous ?
3. Cryptographie : TLS / SSL
-
Vérifiez que vous accèdez bien à la version HTTPS de cette page. Si l'url commence par http://..., remplacez la par https://...
Le protocol HTTPS ajoute une couche de cryptographie (TLS) au dessus de HTTP. Pour inspecter les paquets correspondants, il faut remplacer le filtre par ip.addr == ADDRESS and ssl.
-
Lancez la capture de paquets (avec le bon filtre) et retournez sur le formulaire avec mot de passe.
-
Remplacez le http:// de l'url par un https:// pour accéder à une version HTTPS du même formulaire.
-
Remplissez le formulaire et inspectez les paquets capturés.
Le mot de passe se trouve t'il dans les paquets ?
-
Relancez la capture de paquets, avec le filtre ssl et rechargez le formulaire simple. Faites un diagramme de communication en précisant la taille des paquets échangés.
-
En comparant les tailles des paquets échangés, ainsi que la direction des communications, essayez d'ajouter une description des échanges de paquets SSL de type "application". (Les autres paquets correspondent à des messages permettant de mettre en place la communication...)
4. Serveurs web
Requêtes GET "à la main"
Lorsque vous naviguez sur le web, votre navigateur (qui s'exécute sur votre machine) envoie des requêtes à un serveur web. Les deux requêtes principales sont
-
GET ... pour récupérer des données sur le serveur (par exemple, le contenu d'une page web)
-
POST ... pour envoyer des données (par exemple, le contenu d'un formulaire)
Ces deux requêtes prennent en argument un chemin vers une ressource : le document demandé dans le cas d'un GET, ou la ressource qui doit gérer les données envoyées dans le cas d'un POST.
Le serveur web est un processus qui est associé à un port de la machine sur laquelle il s'exécute. Chaque port est associé à un service. Habituellement, les serveurs web utilisent le port 80.
La commande netcat permet de faire des connections TCP/IP "à la
main". Il suffit de spécifier une adresse et un port :
$ netcat ADDRESS PORTet :
-
les écritures sur l'entrée standard sont automatiquement envoyées au port donné à l'adresse donnée
-
les lectures sur la sortie standard sont automatiquement connectées au port donné à l'adresse donnée
Autrement dit, on peut écrire des requêtes sur l'entrée standard, et recevoir les réponses sur la sortie standard.
Connectez vous sur le port 80 de l'adresse www.perdu.com
avec netcat et envoyez la requête GET pour récupérer le document /index.html.
Une requête GET tient sur 2 lignes:
GET <document> HTTP/1.1 Host: <adresse>
Notes :
-
<document> doit être remplacé par le chemin du document demandé (/index.html dans notre cas),
-
<adresse> doit être remplacé par le le nom de l'hôte du serveur (www.perdu.com dans notre cas),
-
la requête doit être suivie d'une ligne blanche.
La réponse du serveur contient 2 parties :
-
les méta-données,
-
les données.
Quelle est le code de la réponse du serveur ?
Vérifiez que vous obtenez bien le bon contenu en visitant directement le site http://www.perdu.com/index.html.
Attention,
-
il faut taper la requête suffisamment vite. Pour cela, le plus simple est de mettre la commande dans un fichier et utiliser une redirection
CMD < FICHIER... -
il faut que les fins de lignes de votre fichier "requête" utilisent la convention "Windows" : avec nano, il faut appuyer sur les touches "Alt" et "D" en même temps lors du choix du nom de fichier au moment de sauvegarder. (nano affiche que le fichier sera sauvegardé au [Format DOS].) Ce choix sera conservé lorsque vous ouvrirez à nouveau le fichier...
La différence entre les conventions "DOS" et "Unix" est que Unix utilise le seul caractère ASCII "LF" ("line feed", octet 0x0A) alors que DOS utilise les 2 caractères ASCII "CR" et "LF" ("carriage return" et "line feed", octets 0x0F et 0x0A). Vous pouvez consulter https://en.wikipedia.org/wiki/Newline#Issues_with_different_newline_formats pour plus de détails...
Connectez vous sur le port 80 de l'adresse www.perdu.com
avec netcat et envoyez la requête pour récupérer le document
/index.php.
Quelle est le code de la réponse du serveur ?

